一般来说,数据研究人员虽然懂算法的原理,但一般懒得自己去实现一个算法,都会引入一些主流的算法工具模块直接进行应用,一般情况下,这些工具提供的 API 有以下性质:
- 输入参数必须是数据类型,浮点或整型,方便算法进行运算。
- 算法并不知道你输入参数的意义,只是简单计算,然后出结果。
比如很多算法都要你指定空间距离的度量方式,那么你提供的数据就要预先预处理为可以用此方式进行度量的数据后,再传到指定的算法模块!
SkLearn库的preprocessing模块提供了一些的数据预处理的方式,这里简单拿来介绍一下,首先是导入模块和numpy模块。
from sklearn import preprocessing
import numpy as np
对于数值型数据,很多时候我们需要把它投射到0-1的区间,常用的投射有以下三个:
- Z分数规范化
- 最小-最大规范化,通常就是01区间
- 小数定标规范化
Z分数规范化:按标准差偏离度处理
x = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
# 计算每一列的标准差
# 这里可以手算一个,[1,2,0] 纵向第一列的方差 S^2 为2/3,标准差就是 s = 0.81649658
# 也可以通过numpy求出
x.std(axis = 0) # array([ 0.81649658, 0.81649658, 1.24721913])
#使用标准差预处理一下
X_scaled = preprocessing.scale(X)
X_scaled
array([[ 0. , -1.22, 1.33],
[ 1.22, 0. , -0.26],
[-1.22, 1.22, -1.06]])
# 从第一列可以看出 (1-1) / s = 0, (2 -1)/s = 1.22, (0-1)/s = -1.22
# scaled方法将数据预处理为标准差的距离了
TIPS:很多时候做研究,计算出与标准差的距离当然是好的,但到运用到算法里面计算时,可能需要把符号去掉,使用np.abs将结果取绝对值再套入到算法里面。
保存预处理器
数据预处理是一项计算量比较大的事情。比如百万数据量,求标准差偏离度可能已经耗费了不少时间了,如果新来了一条数据,要对新来的一条数据做预处理,很显然不会再把所有的数据拿出来处理计算一次。
可以使用StandardScaler 训练一个预处理模型,后续有了新数据,就可以直接使用已有的模型进行预处理了.
scaler = preprocessing.StandardScaler().fit(x)
scaler.transform(x)
array([[ 0. , -1.22, 1.33],
[ 1.22, 0. , -0.26],
[-1.22, 1.22, -1.06]])
最小-最大规范化:压缩数据到[0,1]区间
标准差预处理已经很简单强大了,但肯定还是不够的,使用MinMaxScaler 可以将数据压缩到[0,1]区间.个人认为这两项都差不多,01区间可能会压缩的均匀一些,标准差压缩更能体现分布的情况,需要根据实际情况去体现了.
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(x)
X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
这个比刚才那个原理上更容易理解,这个函数也可以通过设置参数 feature_range=(min, max) 参数将数据压缩到想要的区间,不一定非得是01。
小数定标规范化:标准化预处理
使用向量空间模型的压缩,有11,12(默认)两种规范,这个有点高端,详细请参考Vector space model。
对于有些强调增长的数据可以使用这种压缩方式。可以让差距拉大。
布尔值预处理
比01区间更简单,布尔值压缩可以通过一个临界值将所有的数据分为0和1.
binarizer = preprocessing.Binarizer().fit(x)
binarizer.transform(x)
array([[ 1., 0., 1.],
[ 1., 0., 0.],
[ 0., 1., 0.]])
文本数据预处理
对于文本类型数据,还是很麻烦的,首先要掌握一个概念:哈希特征,这里简单截取一张WIKI上的图片: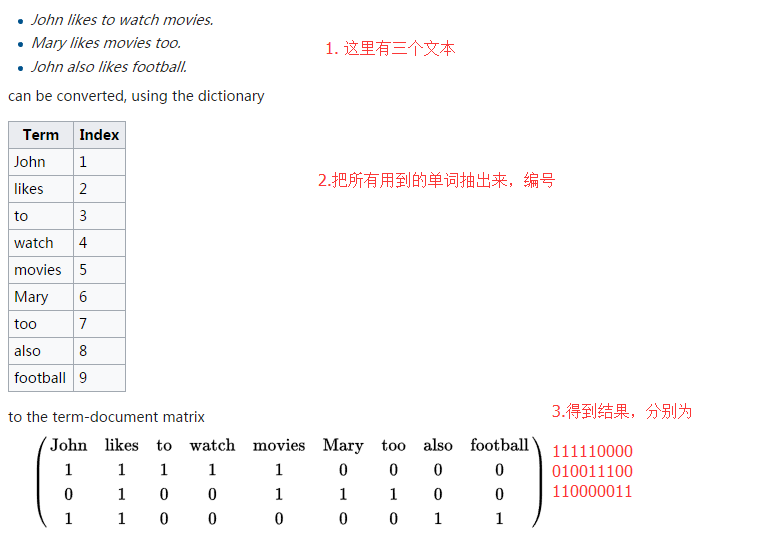
在SKLearn里面,使用DictVectorizer(字典向量化),可以很抽出一组数据的哈希特征
measurements = [
{'city': 'Dubai', 'temperature': 33.},
{'city': 'London', 'temperature': 12.},
{'city': 'San Fransisco', 'temperature': 18.},
]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
vec.fit_transform(measurements).toarray()
array([[ 1., 0., 0., 33.],
[ 0., 1., 0., 12.],
[ 0., 0., 1., 18.]])
vec.get_feature_names()
['city=Dubai', 'city=London', 'city=San Fransisco', 'temperature']
使用FeatureHasher与DictVectorizer有差不多的效果,FeatureHasher有点类似于Java里面的BitMap,一个属性只占用一位更快,占用的内存更小,最多支持2^32-1个属性.
from sklearn.feature_extraction import FeatureHasher
h = FeatureHasher(n_features=10)
D = [{'dog': 1, 'cat':2, 'elephant':4},{'dog': 2, 'run': 5}]
f = h.transform(D)
f.toarray()
array([[ 0., 0., -4., -1., 0., 0., 0., 0., 0., 2.],
[ 0., 0., 0., -2., -5., 0., 0., 0., 0., 0.]])
也可以使用CountVectorizer对文本进行向量化,CountVectorizer可以计数,如上面的,如果一段文字 里面出现两个to,那么得到结果就是001211110
类型数据,在SKLearn里面,也可以使用TfidfTransformer来进行TF-IDF计算。TF-IDF是常用的搜索引擎里面的关键字关键程度计算算法,也就是说一个关键字在一篇文章里面相对出现的次数比较多的时候,权重就会更高,用于文章分类等比较有好处,但目前相关度不高,所以先放着不研究。
那么再回到问题上来,类型数据应该好何压缩呢,其实和FeatureHasher与DictVectorizer差不多,通常把类型组织到一起,压缩成向量。使用OneHotEncoder进行处理,不过有一点要说明,OneHotEncoder不接受字符串的参数,只接受int,所以使用类型数据预处理时,可以手动转成数字。
比如我们有一组数据
| No. | 性别 | 地区 |
|---|---|---|
| 0 | 男 | 湖北 |
| 1 | 女 | 湖南 |
| 2 | 男 | 广东 |
| 3 | 男 | 湖北 |
实际上,我们的性别空间为 [男,女] ,地区空间为 [ 湖北, 湖南,广东],对应上数组的位置,那么可以转换为
| No. | 性别 | 地区 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 0 | 2 |
| 3 | 0 | 0 |
即 [ [ 0 , 0 ] , [ 1 , 1 ] , [ 0 , 2 ] , [ 0 ,0 ] ],那么使用预处理则为
encoder = preprocessing.OneHotEncoder()
encoder.fit( [ [ 0 , 0 ] , [ 1 , 1 ] , [ 0 , 2 ] , [ 0 ,0 ] ])
# 此时,来了一条 【女,广东】的数据,则可以使用encoder序列化为:
encoder.transform([1,2]).toarray()
// array([[ 0., 1., 0., 0., 1.]])
有一点误导了大家,SkLearn的文本类型预处理一般指的是文章等有大量词组组成的数据,并不是我们说的类型数据。