前段时间以笔记的形式记录了一下数据统计的一小部分知识,目前边看边学习数据挖掘,顺便边记录一下,写的肯定会很粗糙 :sweat: 欢迎讨论。
数据挖掘
由于最近太过热门,如果你在技术圈,相信眼睛早已经被各种新闻、报告、科普等文章推荐了一个遍,但是呢,我还是说下我自己的理解。
What is 数据挖掘
我也给不出答案啦 :weary: 一句话:数据挖掘包括但不限于以下知识:机器学习、统计学、数据分析、模式识别、人工智能、商业智能等等。
对于程序员来说,最关心的应该是 机器学习 的部分,但也需要很多基础,比如 统计学 、 纯性代数 等等。
很多人都说可以预测犯罪、预测交通事故、预测人口变化等等,但个人经历太普通了,没有接触过这么高大上的项目,工作了这么多年,和挖掘相关的主要需求也只能想到一些业务上的变化趋势、用户流量的活跃,档次分类、用户的爱好收集及推荐等等看上去很Low的一些需求。(所以自觉求上进 :worried: )
如果真对数据挖掘有兴趣,推荐先复习完概率论中比较重要的章节和一点点的微积分,然后 沉心看书! 、 名牌大学教授的视频 、编码实现,不要把时间浪费在看媒体新闻或别人的架构软文上,这类文章通常是领导们开会时的谈资,对于技术来说百害而无一益!
大数据
大数据是算是较新的概念,主要就一个字:大。

早些年前,数据挖掘的框架在百万级别以下的数据计算的时候,还可以支持,但是对于大型或超级应用程序,比如一个大型程序的某个小分类的数据就达到几到几十个GB(保守来说,比较常见),如果单机跑一个算法,我想把数据一Load进内存,资源就已经被占用完了。所以很久以前数据挖掘只能用来挖掘小中型数据,对于大型数据,有点吃力。
但现在,通过大数据三架马车:HDFS、MapReudce、BigTable将亿级、甚至千亿级数据进行计算变成了可能。个人项目经常见过搞大数据的非常多,然而使用大数据技术来做数据挖掘的还是比较少的,一般都是做综合搜索,比如淘宝(猜的),很久以前,查看我的订单只能按时间段分开查看(分表分库),目前就查看所以时间段的订单了,并支持各种过滤排序分页了。
一句话:不要天天拿数字划界线,如果你公司的服务器设备一台没有办法处理正常业务的数据量,就是大数据。
数据清洗
大多数实际场景中,数据基本上没那么干净,比如我的用户表里面有很多用户填的资料,性别年龄爱好什么的,但是总有那么一部分用户没有填,或故意填错,这样就造成数据挖掘时,缺少值而没有办法进行计算。
另外,最终的清洗肯定是代码去完成,但目前没有一个软件或算法框架能帮我们傻瓜式的完成这些操作,所以,做为数据分析师,清洗过程总是伴随着不段迭代,最终确定一个清洗方案。
数据错误,数据缺失
比如我去做了一份调查问卷,收集上到的数据集里面,很多人没有填收入,那么就是数据缺失。有些人乱填9999999亿,那我肯定是不能拿它做分析的,很明显是数据错误。需要注意的是,有些数据不是真正的缺失,比如职业是学生或无业,就没有收入,没有填这一项,如果要研究收入关联性较大的属性,那么这条数据也不适宜研究,就像你不会把卖楼的传单发给乞丐一样。
数据缺失、错误的处理方法:
- 整条数据忽略
如果数据占整体不大,影响较小,可以忽略掉 - 人工填写缺失值,人工修改错误值
如果是很少的数据,可以手动操作。 - 使用一个全局常量填补
- 使用属性的中心度量(平均数、中位数、众数等)
- 先聚类,再使用同类的中心度量
- 使用回归计算填补
- 也有人使用一随机数生成器根据正态分布或其它分布方式去随机填值
- 其它各种杂七杂八的办法,总之,越接近实际情况,就说明你的数据质量越高,最后挖掘出来的分类器,回归模型就越准确。
噪音,离群点
对于正常的数据,如果不需要那么细,那么其实对你也是会有一定干扰,比如你不需要知道别人的具体收入,但想知道收入情况,那么可以通过分箱来光滑数据,直接把收入分为低收入、中收入、高收入,那么处理起来,看起来也会轻松很多。
具体怎么分,可以使用频数、平均数、边界等去分,甚至,你还可以使用聚类算法由于实际应用的不确定性太多,每一步都是好都结合实际使用。
还有一种方式,维护一个噪音库,比如在淘宝上搜索 “羽容服”,”yurongfu”,都可以对应到”羽绒服”,其实就是输入经过噪音库的处理后,输出正常的数据。
离群点也就是统计里面的异端值,这样的值只能炒作,真正分析中是会影响分析结果的,对于离群点检测这里不多说了,主要有LOF算法,不少库里面都会有API提供。主要如下:
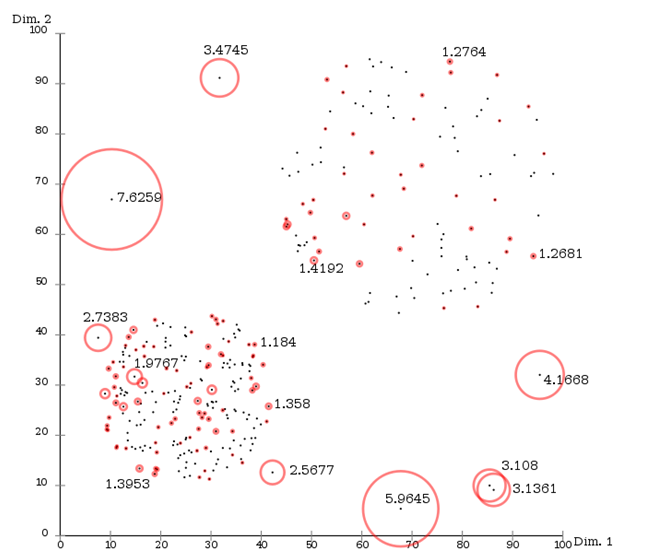
算法思路:对于一个点,找到离它最近的几个点,算距离,再与其它点进行对比,得出LOF值,如上图,LOF的值最大的7.6259和5.9645和其它几个大的,是可以在分析之前清洗掉的,这样后续进行分析挖掘的结果准确度就会更高。
重复检测
如果你去打开一个采集网站,就知道什么叫重复了,上某度搜索,经常前一两页所有的内容都是一样的,全是采集网站,在Google重复检测做的比较好的就很少出现,一般都是原作者最高。
如果你的数据也是这样从多个数据源来的,那么很有可能里面的数据有大量重复,但每个数据源的格式又不一样,如果这样的数据过多,也会影响到我们最终挖掘出来的结果。
就算是单个数据源,也会存在重复,比如使用软件刷的流量就基本没有什么分析的价值,如果做站点体验分析不识别机器访问的行为,那么结果肯定不怎么样。就算是我们普通的项目也有很多需求经常要我们把数据去重后再提供给用户使用。
重复检测主要还是具体情况具体研究,没有万能的方法,主要的难点有两个:1:比较,2:数量太大。如果使用笛卡尔乘积来做一个千万级的数据集的重复检测,结果也可以想象。
小结
数据清洗的质量直接关系后续挖掘模型的质量。很烦又不得不做,这部分其实是最简单但耗费项目时长最大的一部分,对程序员来说,很多数据处理的工具包中都有很多处理数据的方法可以用,贴合业务使用得当可以大大降低这部分的时间,并且提高挖掘的质量。