kNN,原名k-Nearest Neighbor (k近邻算法)。是最简单易懂的一个算法!原理也很简单,在已知的空间中(我们最常想到的就是二维坐标轴),中的一个点,找到K个最近的邻居,大多数邻居怎么样分类,它也就怎么样分类。
下图中,对Xu,k=5的情况下,找到Xu点上最近的5个邻居,有4个是w1类型,1个是w3类型,那么,XU的类型应该是更接近w1.
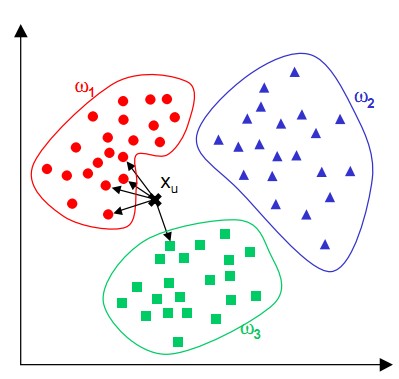
KNN算法是采用测量不同特征值之间的距离进行分类,下面手动造个轮子,自己实现一个KNN算法。
准备数据
这是千里码qlcoder 上的一个题目 : BarryBecker从『1994年美帝人口普查』中抽取的比较干净的上万条数据,数据直接从千里码网站去下载。
TXT的每一行,包括13个属性,依次为:
- 年龄 : 一个整数。
- 工作类型: Private(个体), Self-emp-not-inc(非有限责任公司自由职业), Self-emp-inc(有限责任公司自由职业), Federal-gov(联邦政府), Local-gov(地方政府), State-gov(州政府), Without-pay(无收入), Never-worked(从未工作).
- 教育程度: Bachelors(学士), Some-college(大学未毕业), 11th(高二), HS-grad(高中毕业), Prof-school(职业学校), Assoc-acdm(大学专科), Assoc-voc(准职业学位), 9th(初三), 7th-8th(初中一、二年级), 12th(高三), Masters(硕士), 1st-4th(小学1-4年级), 10th(高一), Doctorate(博士), 5th-6th(小学5、6年级), Preschool(幼儿园).
- 婚姻状态: Married-civ-spouse(已婚平民配偶), Divorced(离婚), Never-married(未婚), Separated(分居), Widowed(丧偶), Married-spouse-absent(已婚配偶异地), Married-AF-spouse(已婚军属)
- 职业: Tech-support(技术支持), Craft-repair(手工艺维修), Other-service(其他职业), Sales(销售), Exec-managerial(执行主管), Prof-specialty(专业技术), Handlers-cleaners(劳工保洁), Machine-op-inspct(机械操作), Adm-clerical(管理文书), Farming-fishing(农业捕捞), Transport-moving(运输), Priv-house-serv(家政服务), Protective-serv(保安), Armed-Forces(军人)
- 家庭角色: Wife(妻子), Own-child(孩子), Husband(丈夫), Not-in-family(离家), Other-relative(其他关系), Unmarried(未婚)
- 种族: White(白人), Asian-Pac-Islander(亚裔、太平洋岛裔), Amer-Indian-Eskimo(美洲印第安裔、爱斯基摩裔), Other(其他), Black(非遗)
- 性别: Female(女), Male(男)
- 资本收益(股票,房产等): 一个整数。
- 资本损失(房产税,股票等): 一个整数。
- 每周工作时长: 一个整数。
- 原国籍:United-States(美国), Cambodia(柬埔寨), England(英国), Puerto-Rico(波多黎各), Canada(加拿大), Germany(德国), Outlying-US(Guam-USVI-etc) (美国海外属地), India(印度), Japan(日本), Greece(希腊), South(南美), China(中国), Cuba(古巴), Iran(伊朗), Honduras(洪都拉斯), Philippines(菲律宾), Italy(意大利), Poland(波兰), Jamaica(牙买加), Vietnam(越南), Mexico(墨西哥), Portugal(葡萄牙), Ireland(爱尔兰), France(法国), Dominican-Republic(多米尼加共和国), Laos(老挝), Ecuador(厄瓜多尔), Taiwan(台湾), Haiti(海地), Columbia(哥伦比亚), Hungary(匈牙利), Guatemala(危地马拉), Nicaragua(尼加拉瓜), Scotland(苏格兰), Thailand(泰国), Yugoslavia(南斯拉夫), El-Salvador(萨尔瓦多), Trinadad&Tobago(特立尼达和多巴哥), Peru(秘鲁), Hong(香港), Holand-Netherlands(荷兰)
- 年收入: 0 or 1,0代表小于等于50k,1代表大于50k。
由于只想记录KNN是如何工作的,所以,对于数据的加权,转换等暂时不在这里讲解,我就当是一条数据,且经过过滤后,认为有用的值只有 年龄,收益,负债,工作时长,四个属性对我的分析有用。而且,我也只用了其中的10条数据作为训练集。
39,"Private","HS-grad,Never-married,Sales,Unmarried,Black,Female,0,0,40,United-States",0
42,"Private","Masters,Married-civ-spouse,Sales,Husband,White,Male,15024,0,50,?",1
26,"Private","HS-grad,Divorced,Other-service,Unmarried,White,Female,0,0,35,United-States",0
27,"Private","Assoc-voc,Never-married,Exec-managerial,Own-child,White,Male,0,0,40,United-States",0
52,"Private","9th,Widowed,Adm-clerical,Unmarried,White,Female,0,0,40,United-States",0
50,"Local-gov","Some-college,Divorced,Other-service,Unmarried,Black,Female,0,0,40,United-States",0
51,"Private","HS-grad,Married-civ-spouse,Machine-op-inspct,Husband,White,Male,0,0,45,United-States",1
51,"Federal-gov","HS-grad,Married-civ-spouse,Adm-clerical,Husband,White,Male,0,0,40,United-States",1
40,"Private","HS-grad,Married-civ-spouse,Sales,Husband,White,Male,0,0,40,United-States",1
61,"Private","7th-8th,Widowed,Farming-fishing,Not-in-family,Black,Male,0,0,40,United-States",0
算法
就不多写那些文件数据相关的代码了,numpy有很方便的文件导入API,矩阵构建,我这里直接用硬代码构建。
# 训练集,这里手动把上面10条数据的 年龄,收益,负债,工作时长 四个属性组写到数组里面
trainData = np.array([
[39,0,0,40],
[42,15024,0,50],
[26,0,0,35],
[27,0,0,40],
[52,0,0,40],
[50,0,0,40],
[51,0,0,45],
[51,0,0,40],
[40,0,0,40],
[61,0,0,40]
])
# 训练结果 对应上面数组每个对象的最终结果,即年收入
trainLabel = np.array([0,1,0,0,0,0,1,1,1,0])
然后就是KNN的算法了,这里面不考虑数值大小,权值等杂七八的情况,就认为每个数都是差不多的。
'''
最简单的KNN模型,属性全部都为数值,不带权值
'''
class KNN:
#构造器,可以定义K的个数,不传就是3个
def __init__(self,k=3):
self.k = k
print("Build Knn",self.k)
#载入数据(训练样本)
def loadData(self,dataSet,labels):
self.dataSet = dataSet
self.labels = labels
self.size = dataSet.shape[0]
#核心方法:计算结果
def getResult(self,data):
# 使用欧氏距离计算数据对每个元素距离空间
diff = np.tile(data,(self.size,1)) - self.dataSet
diff = diff ** 2
diff = diff.sum(axis=1)
distance = diff ** 0.5
# 将距离由近到远排序
distance = distance.argsort()
classification = {}
# 取出最近的k个元素
for i in range(self.k):
classification[self.labels[distance[i]]] = classification.get(self.labels[distance[i]],0) + 1
# 再取K个元素中类型最多的那个,返回
sorted(classification.items())
classification = sorted(classification.items(),key=lambda a:a[1],reverse=True)
return classification[0][0]
OK,一个没什么实际作用的KNN算法大概就是这样,numpy的数据运算实在是太整代码行数了,而且性能还不错(numpy是用c语言写的,并非python),当然还有更省行数的方法,使用sklearn包里面自带完善的KNN算法,我们先用我们自己的KNN进行测试吧,这样才有成就感。
# 构造KNN分类器,K的个数为3
knn = KNN(3)
# 导入已知的数据
knn.loadData(trainData,trainLabel)
# 给未知的数据进行分类
knn.getResult(np.array([35,55,0,20])) # 0
knn.getResult(np.array([26,4,0,35])) # 0
knn.getResult(np.array([42,0,0,50])) # 1
说明
如果懂一些常识,就可以看出刚才的代码是玩具级别,不能拿来实用,比如资产流入 15024 远大于 其它参数如年龄、工作时长等,真正使用会产生很大的误差。而且,对于过高维度的数据来说欧氏距离也不一定100%合适。
通常,可以使用z分数法将数据映射到0-1区间再做运算,结果会准确很多。
另外,还有实际性,有时我们可以使用闵氏距离或上边距距离代替欧氏距离来增加相应的实用度,这也是我们后续使用工具包时,要经常想到的。
使用sklearn
一般情况下使用算法肯定不会自己写代码了,在SkLearn里面KNN的API是的neighbors里面,只用几行代码就可以完成刚才的事情了,测试了一下,结果和我自己写的的是一样的,呵呵
from sklearn import neighbors
knnClass = neighbors.KNeighborsClassifier(n_neighbors=3)
knnClass.fit(trainData,trainLabel)
knnClass.predict([[35,55,0,20]]) # 0
knnClass.predict([[26,4,0,35]]) # 0
knnClass.predict([[42,0,0,50]]) # 1
当然sklearn的功能远强大我自己手写的代码,除了能接受 n_neighbors=3 参数 外,还能接受更多参数,定制内部算法,度量方式等。
小结
如果看懂了原理,那么KNN的优缺点就很明显,主要优点是准确性不错,缺点就是计算量太大,比如我有千万级的数据,(先不考虑如果放在内存做矩阵的问题),我每对一条数据进行一个分类的计算量就大的惊人,就不用说我们经常需要批量处理好多数据了。