有个成语叫 物以类聚,人以群分,就比较形象的解释了聚类的现象。聚类属于无监督学习,提供数据时,只需要提供对应算法的分析参数,不需要提供每条数据所属的类别。
聚类的算算法有很多,用的最多的是 K-Means 和 DBScan 算法,这里也只简单介绍这两种。 其它的聚类算法也有很多,比如: K-medoids、 近领传播算法 、Birch等等。
K-means
K-Means 是比较常用的聚类方法之一。原理也很容易理解,K-Means算法必须有一个参数K,代表最终聚出类别的个数。其它参数可根据使用的算法库提供的API进行扩展,比如距离度量方式等,初始点的放置等。
K-Means 的流程如下
- 初始化数据,在数据所在的空间中放置K个点,(K个Label)
- 计算空间中所有的点分别到这K个点的距离,离每个点最近的那个( Label ),就是那个点的 Label
- 得到了K个簇(每个Label都有离自己最近的一群小弟了),每个簇的点,重新计算中心点,做为新的K个点的位置( Label 的新位置)
- 重新计算 2-3-2-3,最后结果差不多不变或变化很小时,聚类就稳定了。
SKLearn 中的K-means
在 SKlearn 里面,直接使用 sklearn.cluster.KMeans 就可以生成一个 K-means 算法模型。先看看初始化的参数:
| 参数 | 说明 |
|---|---|
| n_clusters | 指定聚类中心的个数 |
| init | 初始化聚类中心的方法 |
| max_iter | 最大跌代次数,默认为300 |
| data | 需要聚类的数据 |
| label | 聚类后数据所属的标签 |
| fit_predict | 计算簇中心以及为簇分配序号 |
一般情况下,只用指定 n_cluster(即最终要聚成类别的数量) 即可。如下:
import numpy as np
from sklearn.cluster import KMeans
km = KMeans(n_clusters=4)
label = km.fit_predict(data)
expenses = np.sum(km.cluster_centers_,axis=1)
# print xxxxxx
需要注意 Sklearn 的 K-Means 默认使用的是欧氏距离,而且没有测量距离方法相关的设置参数!
DBSCAN
DBScan 是一种基于密度的聚类算法。与 K-mean 不同的是,不需要指定K的个数,最终结果也不确定有几类,但是DBSCAN 需要指定EPS及领域MINPTS内的个数(核心与边界的区分)
核心点:给定距离内有一定数量邻居的点
边界点:没有超过一定数量邻居,但是属于核心点邻居的点
噪音点:其它的点
如图:当设置 MINPTS = 5 时,红色点在一定范围内都有5个或以上的邻居,那么是核心点,在这些红点的范围内的邻居则是边界点,其它的则是燥音点。
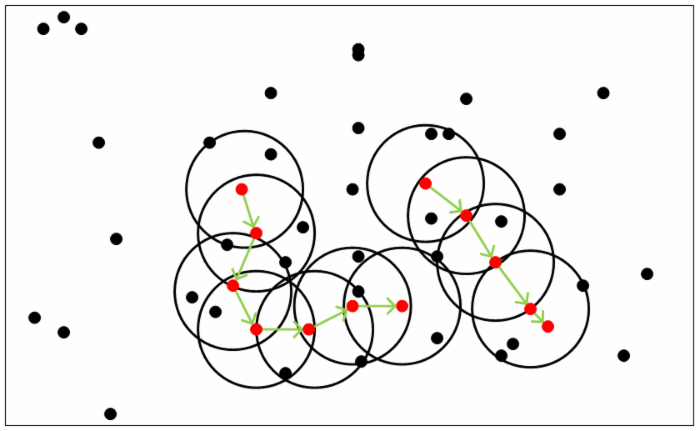
当这些点组成的空间相连的并集,就是一个簇,最终会归为一类。
SKLearn 中的 DBSCAN
| 参数 | 说明 |
|---|---|
| eps | 两个样本被看做是邻居节点的最大距离 |
| min_samples | 簇的样本数 |
| metric | 距离的计算方式 |
import numpy as np
import sklearn.cluster as skc
db = skc.DBSCAN(EPS=0.01,MIN_SAMPLES=20).fit(data)
labels = db.labels_
# print xxx